We believe in-language simplification is the right kind of help, and the reason is pedagogical. Stephen Krashen’s Input Hypothesis holds that we acquire language through comprehensible input — language we can understand that sits just beyond our current level, often written as “i+1”. Input that is too hard is noise; input that is too easy teaches nothing new.
Easy-language simplification lowers complexity while keeping the learner immersed in the target language. A learner in a German lecture receives German they can actually follow — shorter sentences, common words, one idea at a time — and keeps building acquisition from real target-language input. An English translation would make the sentence comprehensible too, but it removes the German exposure entirely, which is the thing the learner came for.
Translation answers “what did they say?” Simplification answers “what did they say, in words I can learn from?” Only the second keeps the learner inside the language they are trying to acquire.
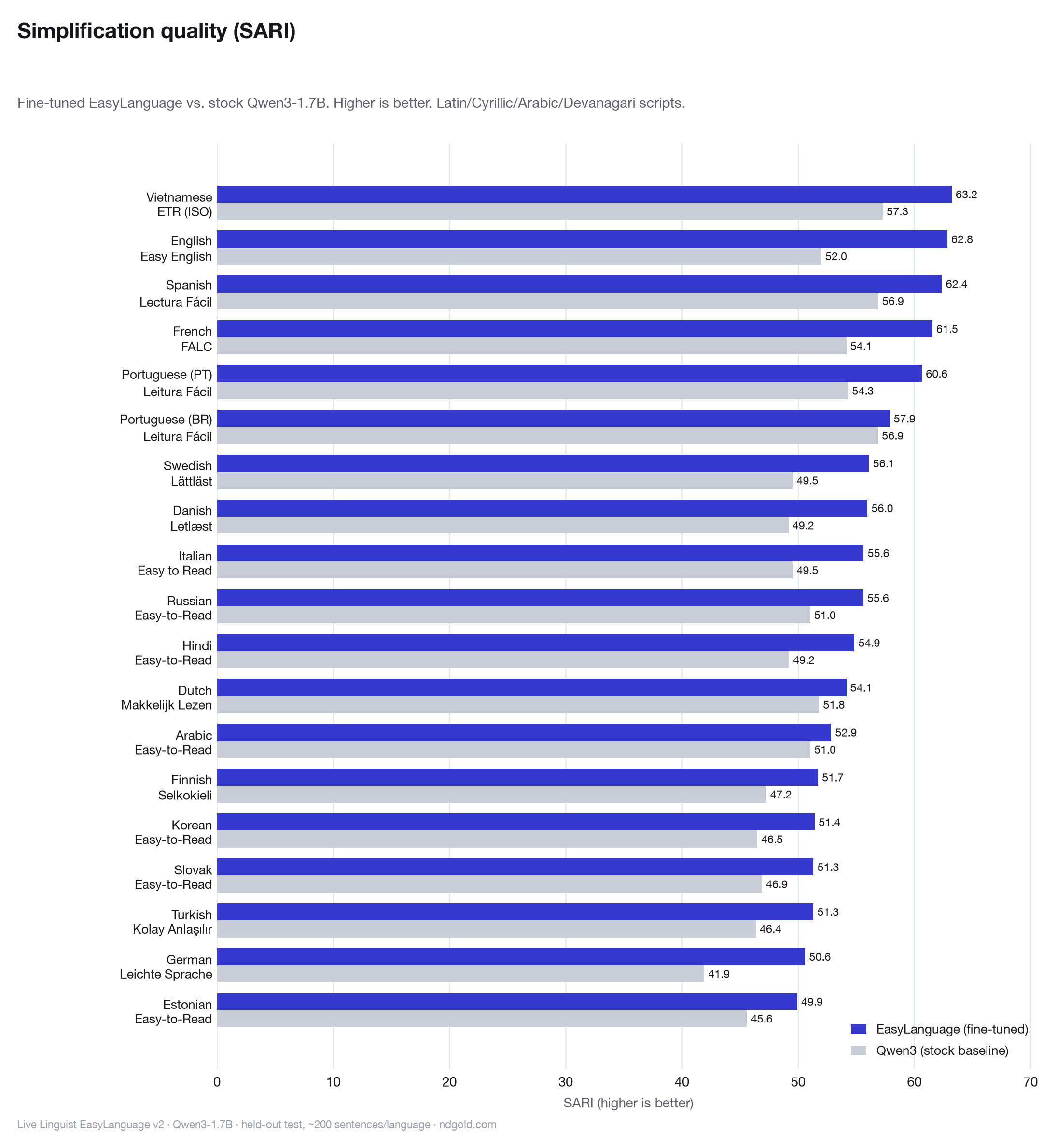
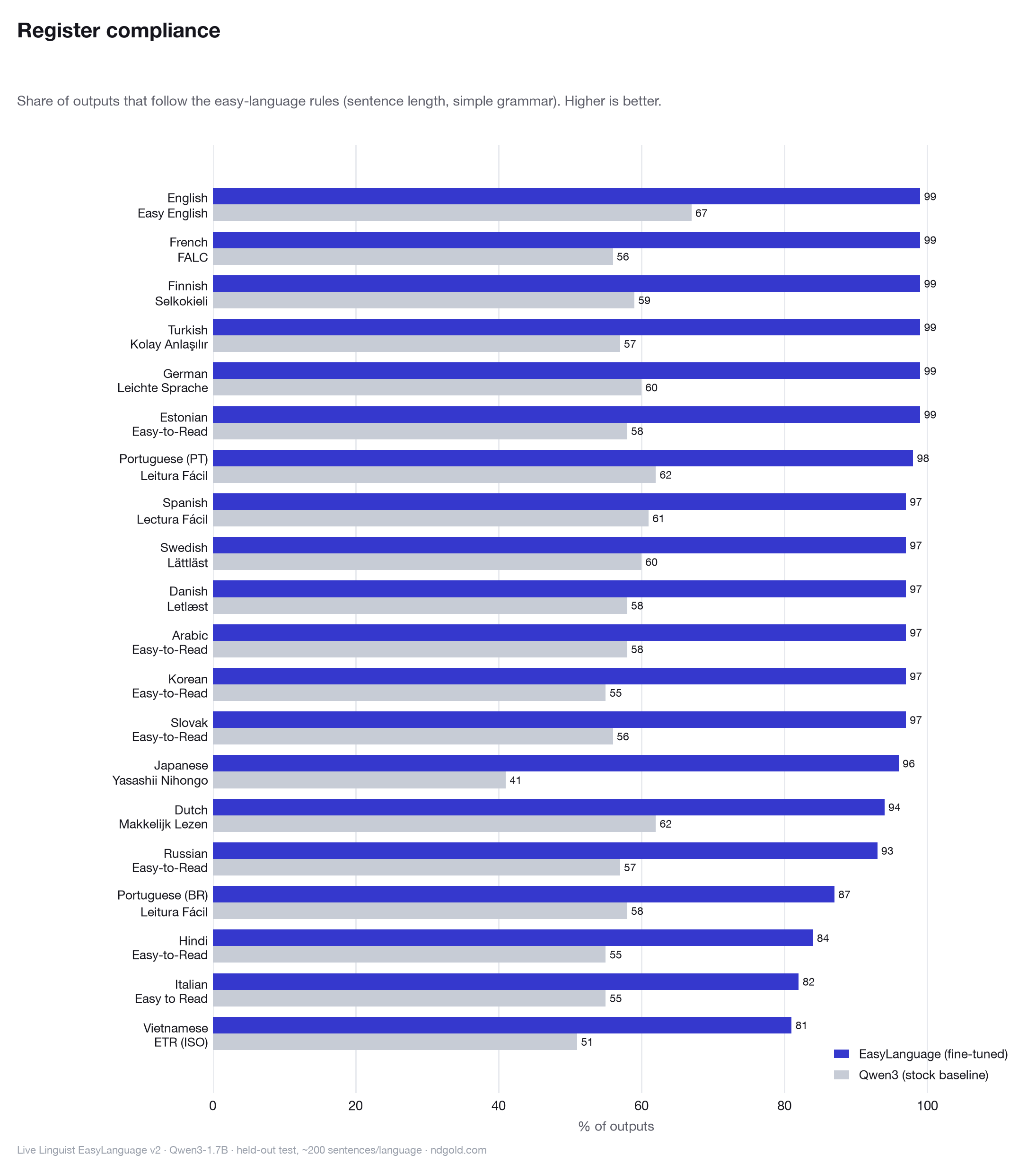
The same property carries a parallel accessibility value. Easy-language standards — Leichte Sprache, FALC, Lectura Fácil, Selkokieli, and the pan-European Easy-to-Read framework — were developed so that people with cognitive disabilities and low-literacy readers can take part in public and everyday life. A tool that produces compliant easy language serves those readers directly, in their own language. v2 extends that reach to twenty of them.
This is the project’s rationale, grounded in second-language-acquisition theory and established accessibility standards. It is not a clinical claim about learning outcomes.